




Data Science คืออะไร? สายงานนี้ต้องทำอะไรบ้าง มาดูกันชัดๆ

| |
||||
| แหล่งที่มา : www.growthbee.com | วันที่โพสต์ : 20 พ.ค. 2561 | |||
| Data Science คืออะไร? สายงานนี้ต้องทำอะไรบ้าง มาดูกันชัดๆ | ||||
 |
||||
Data Science คืออะไร |
||||
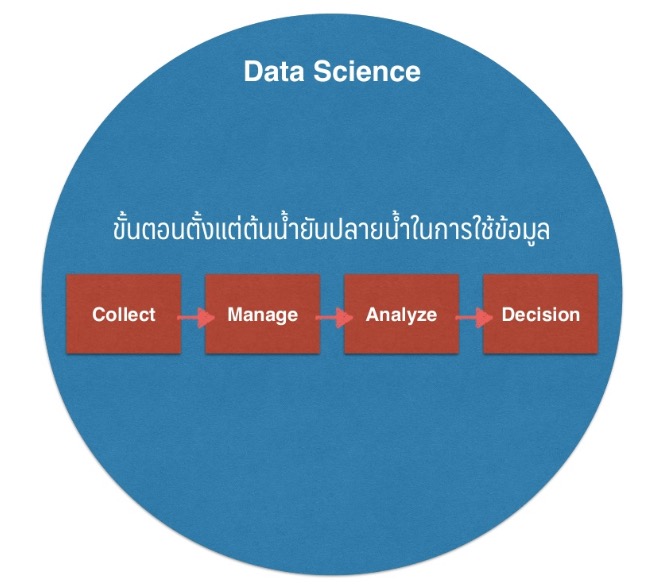 ขั้นตอนการทำ Data Science จาก สไลด์ของแอด เองครับ |
||||
| Data Science หมายถึง การนำข้อมูลมาใช้ประโยชน์ โดยครอบคลุมตั้งแต่ขั้นตอนการเก็บข้อมูล (Collect) > การจัดการข้อมูล (Manage) > การวิเคราะห์ข้อมูล (Analyze) > ไปจนถึงขั้นตอนการนำข้อมูลมาช่วยตัดสินใจ (Decision) | ||||
สำหรับ Data Science ในภาษาไทย ถ้าแปลตรงตัวก็คือ “วิทยาศาสตร์ข้อมูล” แต่แอดชอบคำว่า “วิทยาการข้อมูล” จากคอร์สของมหาวิทยาลัยในไทยแห่งหนึ่งที่แอดหาข้อมูลมาล่าสุด คิดว่าฟังดูคล้าย ๆ กับ “วิทยาการคอมพิวเตอร์ (Computer Science)” ดีครับ Data Science = Computer Science + Maths & Stats + Business Domain Expert ? |
||||
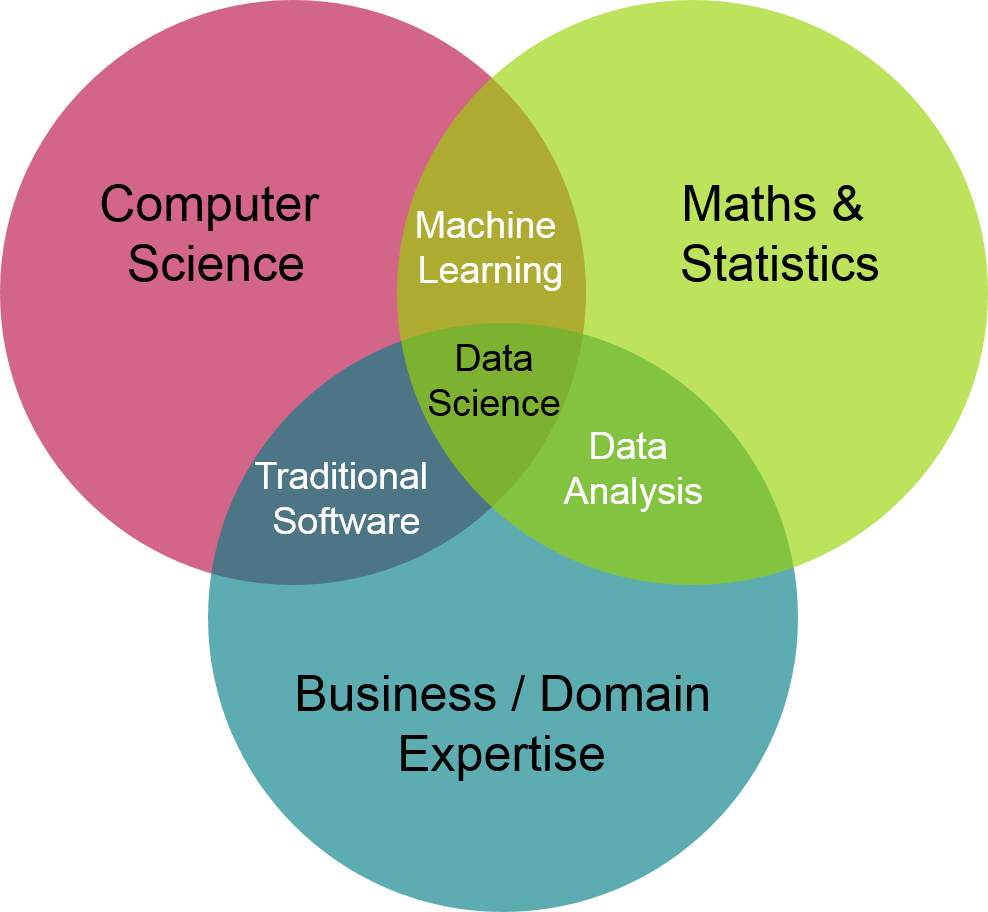 Venn Diagram ของ Data Science – ขอบคุณรูปภาพจาก ICAEW |
||||
| มีหลาย ๆ แห่งบอกว่าการทำ Data Science คือการที่วงกลม 3 วงมาตัดกัน ได้แก่: 1.Computer Science – วิทยาการคอมพิวเตอร์ เช่น การเขียนโปรแกรม, อัลกอริธึม, โครงสร้างข้อมูล (Data Structure) 2.Maths & Statistics – คณิตศาสตร์ และสถิติ 3.Business / Domain Expertise – ความรู้ด้านธุรกิจ อันนี้แอดคิดว่าค่อนข้างถูกต้อง แต่ไม่ 100% เพราะการทำ Data Science ไม่ได้จำกัดแค่วงกลม 3 วงด้านบน เราจำเป็นต้องรู้ศาสตร์เฉพาะทางในการจัดการกับข้อมูลเพิ่มเติมอีกด้วยครับ ซึ่งสิ่งที่วงกลมเหล่านี้ขาดไป คือ ด้านของ Data Engineering งานของสาย Data Science ต้องทำอะไรบ้างขั้นตอนการทำ Data Science ที่แอดอธิบายไปด้านบน (Collect > Manage > Analyze > Decision) เป็นภาพกว้าง ๆ ครับ เราจะมาเจาะลึกกันว่าแต่ละขั้นตอนต้องทำอะไรกันบ้าง เราเรียก Process นี้ตั้งแต่ต้นจนจบว่า “การนำข้อมูลมาทำให้เกิดคุณค่า” หรือ Data Science Value Chain ครับ |
||||
| 1. Collect เก็บข้อมูล | ||||
 ตัวอย่างข้อมูลคนเข้าเว็บไซต์จาก Google Analytics ที่เราสามารถดึงผ่าน Google API มาใช้ได้เลย |
||||
| การเก็บข้อมูลสามารถทำได้หลายวิธี ซึ่งขึ้นอยู่กับข้อมูลที่เราต้องการเก็บด้วยครับ เช่น - ถ้าต้องการเก็บ Log การใช้เว็บไซต์ ก็อาจจะเขียน JavaScript วางไว้ในเว็บไซต์ของเรา เพื่อเก็บการกระทำต่าง ๆ ของผู้ใช้ - ถ้าต้องการเก็บข้อมูลจากเว็บไซต์อื่น เราต้องเขียนโปรแกรมดึงข้อมูลทาง API หรือ Scrape ข้อมูลจากหน้าเว็บไซต์ - หรือสำหรับคนที่หัด Data Science ผ่านเว็บไซต์อย่าง Kaggle ก็จะเห็นว่าข้อมูลเค้าเก็บมาให้เราเรียบร้อยแล้ว เราสามารถ Download แล้วนำมาใช้ได้เลย ซึ่งพอเราเก็บข้อมูลมาแล้ว ก็ต้องมาคิดว่า… “จะเก็บข้อมูลไว้ที่ไหนดี” ซึ่งเป็นที่มาของข้อต่อไปนั่นเองครับ |
||||
| 2. Manage จัดการข้อมูล |
||||
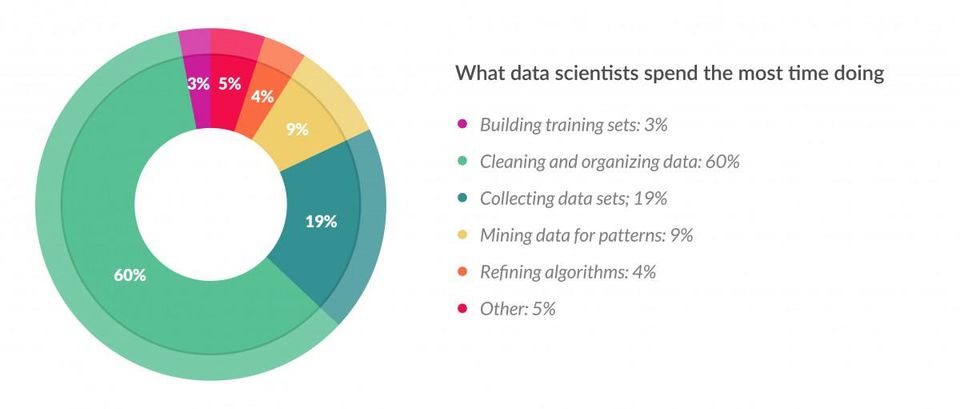 60% ของเวลาในการทำงานทั้งหมดของ Data Scientist มาจาก Data Wrangling นั่นเอง – ขอบคุณรูปภาพจาก Forbes |
||||
|
หลังจากทำความสะอาดข้อมูลเสร็จแล้ว ก็ได้เวลาจัดเก็บลงฐานข้อมูลครับ ซึ่งปัจจุบันมีฐานข้อมูลหลากหลายแบบให้เราเลือกใช้ เช่น SQL หรือ NoSQL, OLTP หรือ OLAP ฯลฯ เราก็ต้องเลือกให้ถูกต้องครับ นอกจากนั้นขั้นตอนนี้ยังต้องคอยดูเรื่อง Policy ของบริษัท หรือของรัฐบาลด้วยครับ เช่น บริษัทอาจจะมีนโยบายเก็บข้อมูลย้อนหลัง 365 วัน เราก็ต้องเตรียมสคริปต์ในการล้างข้อมูลเมื่อถึงเวลาที่กำหนด ทีนี้พอเราเก็บข้อมูลไว้พร้อมใช้เรียบร้อยแล้ว ก็ได้เวลาดึงมันมาใช้ประโยชน์กันครับ |
||||
3. Analyze วิเคราะห์ข้อมูล
|
||||
| ขั้นตอนนี้คนให้ความสนใจเยอะมากที่สุดในปัจจุบันนี้ เพราะ Buzzword ต่าง ๆ เช่นคำว่า Machine Learning หรือ Deep Learning ก็อยู่ในขั้นตอนนี้นั่นเอง | ||||
 |
||||
| สำหรับการวิเคราะห์ข้อมูล เราอาจจะต้องใช้ความสามารถในการเขียนโปรแกรมครับ ซึ่งแอดเคยเล่าให้ฟังเรื่อง 7 ภาษาโปรแกรมมิ่งที่สำคัญสำหรับ Data Science ไว้แล้ว สามารถเข้าไปหาข้อมูลได้เลยครับ
จากขั้นตอนที่แล้ว พอเรามีข้อมูลพร้อมใช้เรียบร้อย ก็ได้เวลานำมาวิเคราะห์เพื่อหาสิ่งที่น่าสนใจในข้อมูลครับ ซึ่งขั้นอยู่กับว่าโจทย์ที่ต้องการแก้ไขคืออะไร ผมคิดว่าเราแบ่งได้เป็น 2 โจทย์หลัก ๆ ในการวิเคราะห์ดังนี้ สิ่งที่ผมเห็นหลาย ๆ คนเข้าใจผิด คือ เข้าใจว่า Data Science ต้องทำสร้าง Model ตลอดเวลา ต้องไปใช้ Random Forest, XGBoost ฯลฯ ซึ่งจริง ๆ แล้วบางปัญหาแค่ต้องการ Insights ไม่ใช่ Model ในการแก้ไข ในขั้นตอนนี้เราจะได้ใช้ประโยชน์จากการทำ Data Exploration ด้วย เพราะหลายครั้งการพลอตกราฟมาดู Distribution ก็มีประโยชน์กว่าการดูเฉพาะสถิติตัวเลขเฉย ๆ ครับ ลองดูจากตัวอย่างด้านล่างจะเห็นได้ชัดครับ |
||||
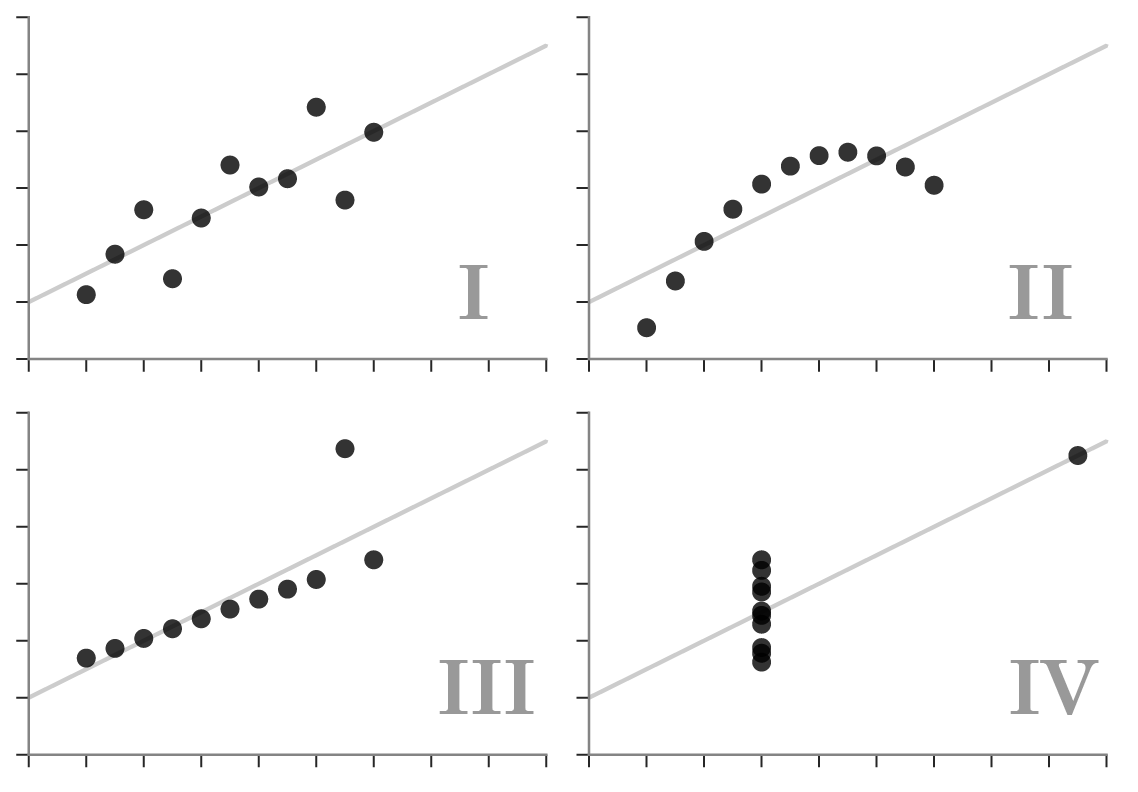 ทุกกราฟในนี้มีค่า Mean, SD, Correlation เท่ากันหมด แต่หน้าตา Distribution ไม่เหมือนกันเลย ถ้าเราเห็นแค่ตัวเลขแล้วสรุปจากตัวเลขก็จะเข้าใจข้อมูลผิดไปครับ – ขอบคุณรูปภาพจากคุณ Justin Matejka, George Fitzmaurice (2017) Autodesk Research |
||||
| พอจบขั้นตอนนี้ เราก็จะได้ผลวิเคราะห์ (หรือโมเดล) เพื่อนำไปใช้ประโยชน์กับธุรกิจจริง ๆ แล้วครับ |
||||
4. Decision นำข้อมูลมาช่วยตัดสินใจ |
||||
| ขั้นตอนนี้ เราที่ทำงาน Data Science มีหน้าที่สรุปผลวิเคราะห์ให้เข้าใจง่าย ๆ เพื่อนำไปเสนอผู้ร่วมงานในฝ่ายบริหารครับ ซึ่งเป็นที่มาว่าทำไมหลายแห่งบอกว่า Data Scientist ต้องมี “ความสามารถในการสื่อสาร” (Communication Skill)
ในการแสดงผลวิเคราะห์ เราไม่จำเป็นต้องพูดปากเปล่าเสมอไปครับ เราสามารถแสดงเป็นรูปภาพให้ฝ่ายบริหารเข้าใจง่ายขึ้นได้ ความสามารถด้าน Data Visualization จะมีประโยชน์มากครับ |
||||
 ตัวอย่างการทำ Data Visualization แสดงราคาหุ้น |
||||
| สำหรับท่านที่สนใจด้านนี้ แอดขอแนะนำหนังสือ Storytelling with Data เขียนโดยอดีต People Analytics Manager ที่ Google และตีพิมพ์โดย Wiley ครับ เป็นหนังสือที่เข้าใจง่ายดีมาก ๆ
(แต่แอดหาซื้อตามร้านไม่ได้ T_T เลยเป็นเหตุผลที่แอดซื้อ Kindle มาเมื่อปีที่แล้วนี่เอง) หลังจากเราอธิบายผลวิเคราะห์ให้เค้าแล้ว เราก็สามารถแนะนำแนวทางปฏิบัติโดยอิงจากผลวิเคราะห์ของเราได้ ซึ่งแปลว่าเราต้องมีความเข้าใจในธุรกิจ และเข้าใจถึงปัญหาที่เกิดขึ้นด้วยครับ |
||||
| เราต้องทำเป็นทุกอย่างเลยหรือเปล่า? |
||||
| จากด้านบนจะเห็นว่างานของ Data Science มันกว้างและเยอะมาก หลายคนอาจจะสงสัยว่าเราต้องทำเป็นทุกอย่างที่ลิสต์อยู่ด้านบนเลยมั้ย? |
||||
| คำตอบคือ… เราไม่จำเป็นต้องรู้ทั้งหมด
ในสายงาน Data Science จะมีหลายตำแหน่งงานที่มาช่วยกันทำในแต่ละส่วนครับ หลายคนอาจจะเคยเห็นบริษัทรับตำแหน่ง Data Engineer, Data Analyst, Data … ซึ่งคนเหล่านี้แหละที่จะรับผิดชอบในแต่ละส่วนครับ ยกเว้นว่าเราคุมตำแหน่ง Management ระดับสูงเกี่ยวกับ Data Science ในองค์กรใหญ่ อันนี้เราต้องเข้าใจทุกกระบวนการ แต่ไม่ต้องทำเองเป็นหมดก็ได้ครับผม |
||||
| ขอบคุณข่าวจาก : growthbee |
||||
